Work related to Computer Vision & Image Processing
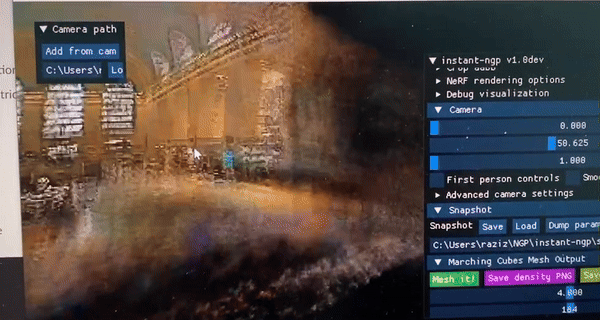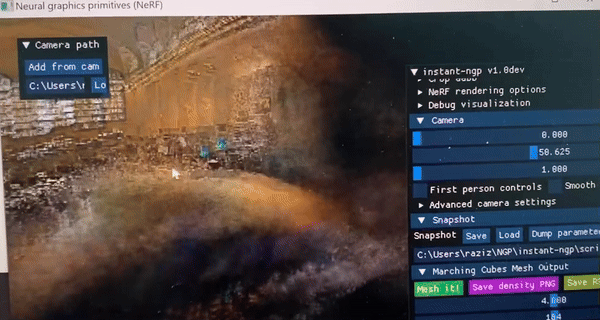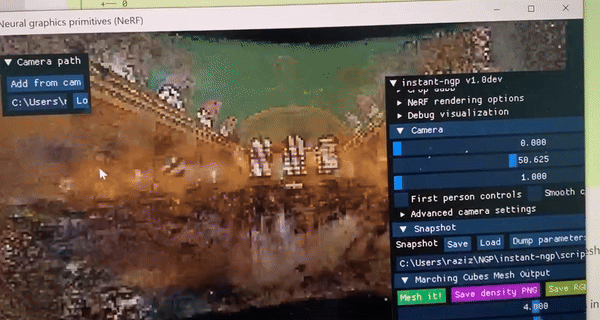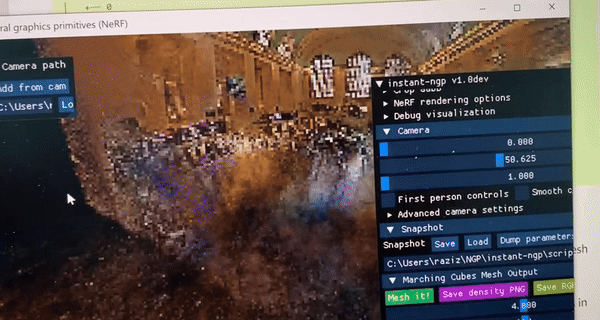
Some casual Instant-NGP/Nerf results:
I've ran Instant-NGP (a nerf technique) that uses MLPs to generate 3D scenes from 2D images only.
It was even able to create 3D scenes for areas that were absent in the 2D image. How amazing!
This could automate the work of creating 3D contents with Unreal to some extent.
Fig 1 & 2 : 3D Interiors
Fig 3 & 4 : 3D exteriors
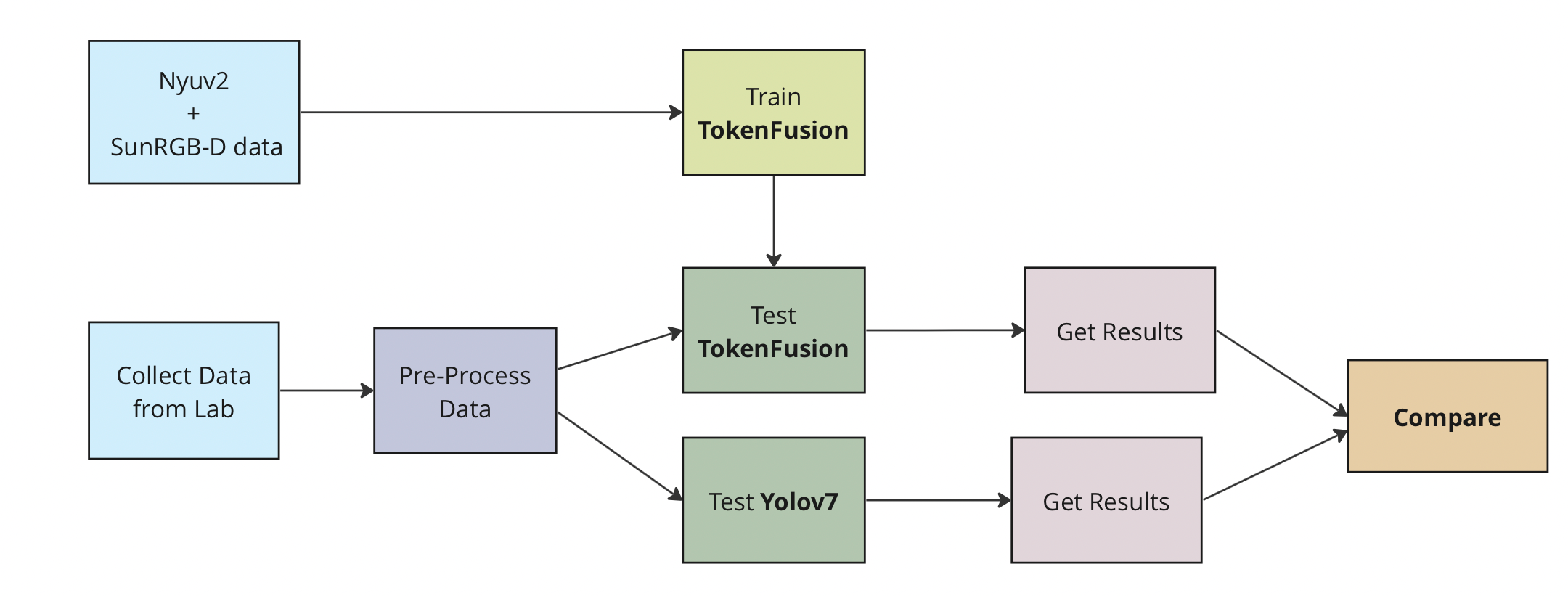
PROJECT 1: RGB-D Fusion for Segmentation on Indoor data for Autonomous Wheelchair
Research Project - Worked on image+depth fusion techniques with transformer networks and with traditional YOLOV7 for segmentation
on indoor dataset used for autonomous wheelchair scenario.
Problem - Automate the motorized wheelchair by creating an understanding of the surrounding scene
Solution - Using various segmentation methods, analyze the pros and cons of the outputs based on the
model architectures, and improve the performance on the collected dataset.
With the goal of contributing to the automation of a motorized wheelchair, this research project focuses on
deep learning approaches and data fusion techniques on indoor data. The objective of the research project is to
perform segmentation on indoor dataset collected manually from a camera at Carleton University.
I mainly explore and compare two segmentation methods, traditional neural networks Yolov7 and
a multimodal encoder-decoder transformers TokenFusion, in terms of
performance and outputs.
Yolov7 : solely depends on image inputs with traditional
CNNs for segmentation tasks. Originally trained on a much larger dataset (MS Coco dataset) of only images. Yolo originally performs object detection,
but version 7 can also perform segmentation.
TokenFusion: transformer method depends on multimodal data (Image and depth), fusing images with
corresponding depths in the encoder-decoder models. Originally trained on a smaller dataset (Nyudv dataset). Can perform both segmentation and object detection
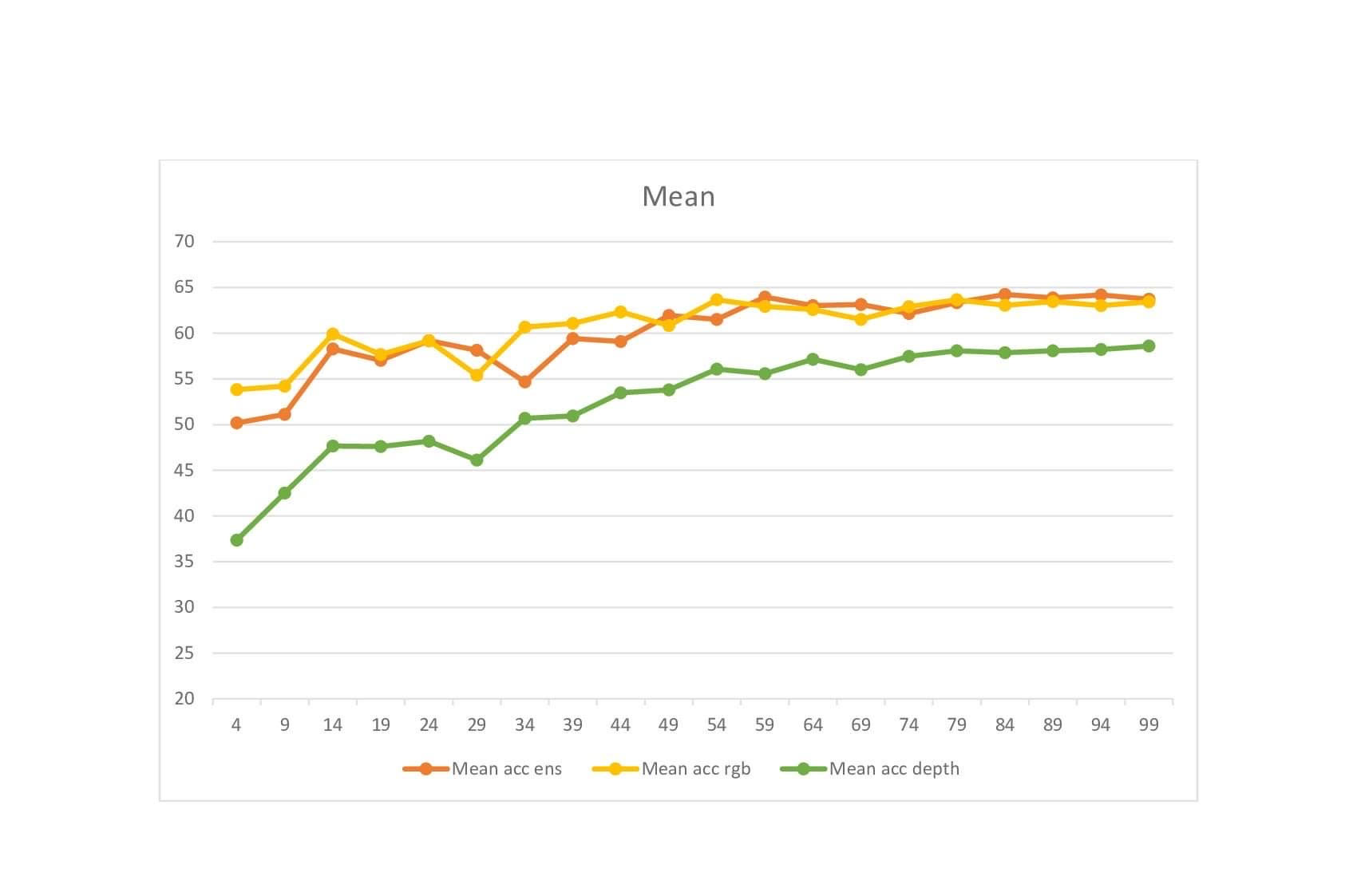
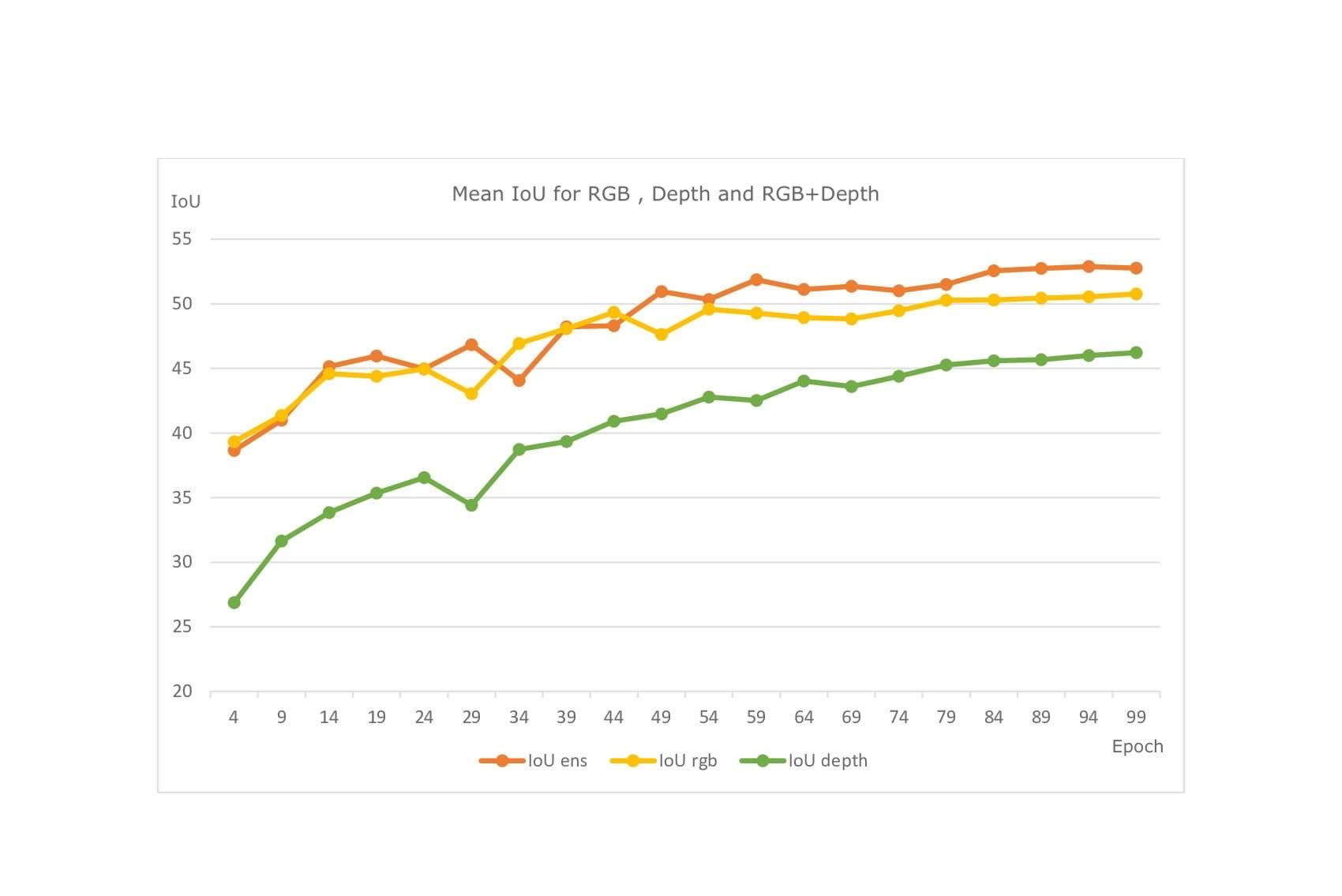
The results demonstrate that the inclusion of depth images
are highly beneficial for segmenting the interior structure of the indoor environment, and the performance based on
training, time and accuracy are also compared between the two models. Both the methods are quite different in terms of
input modalities and backbone networks, and the advantages and disadvantages of both methods are discussed.
Questions I asked myself while using the ML model:
All these models are shown to perform really well on the dataset they were trained on, but does it
actually perform well on ANY indoor dataset? Let's explore!
If it doesn't, what are the possible reasons? What should be fine-tuned?
What information is it failing to understand or percieve properly?
Is this a generalization problem?
Is this a data preprocessing problem?
*If you're interested to discuss more or view the code, please Email Me .
Due to privacy constraints, you will need extra permission from the Professor to view the code.
First Image : Input Image (RGB)
[Collected from Intel RealSense D455 camera sensor]
Second Image : Depth (D)
[Collected from Intel RealSense D455 camera sensor]
Third Image : Output from Yolov7
Fourth Image : Output from TokenFusion
PROJECT 2 : GANs (Generative Adversarial Networks) on Limited Data
Problem : Shortage of Image data with labels
Solution : Synthetically generate image data with Generative AI Models
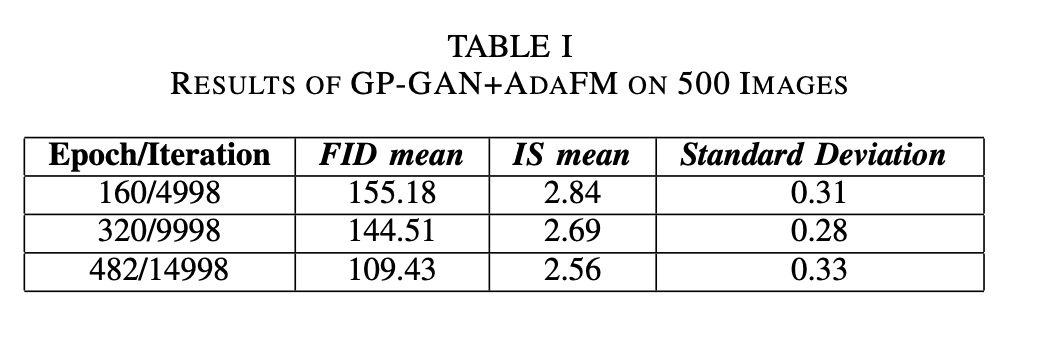
Used pre-trained StyleGAN2, GP-GAN and SIN-GAN trained on Breast Cancer images.
It is important to see how the model performs inititally without fine-tuning.
To no surprise, the model performed horrible initially. But this gives an insight to where the
problem might be and what needs to be changed.
Fine-tuned learning rates and decay values
Changed the regularizor loss to LeCam Loss to improve the generalization of the images.
Synthetically generated better images based on different batch sizes
If more GPU power was available, it is possible to attain further detailing of the generated images.
Questions that still need to be answered:
How do you defined good results here? I know the loss and FID metrics provide an insight,
but even for us humans, it is not clear how to measure goodness of abstract images. If you have any insights,
please Email Me .
Original Images Fed
Synthetically Generated Images
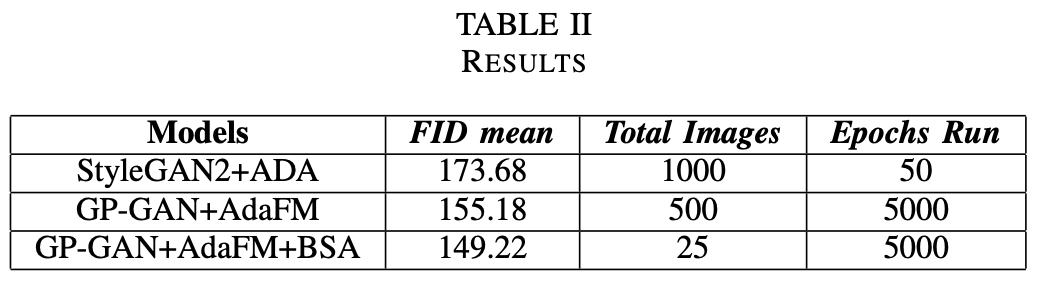
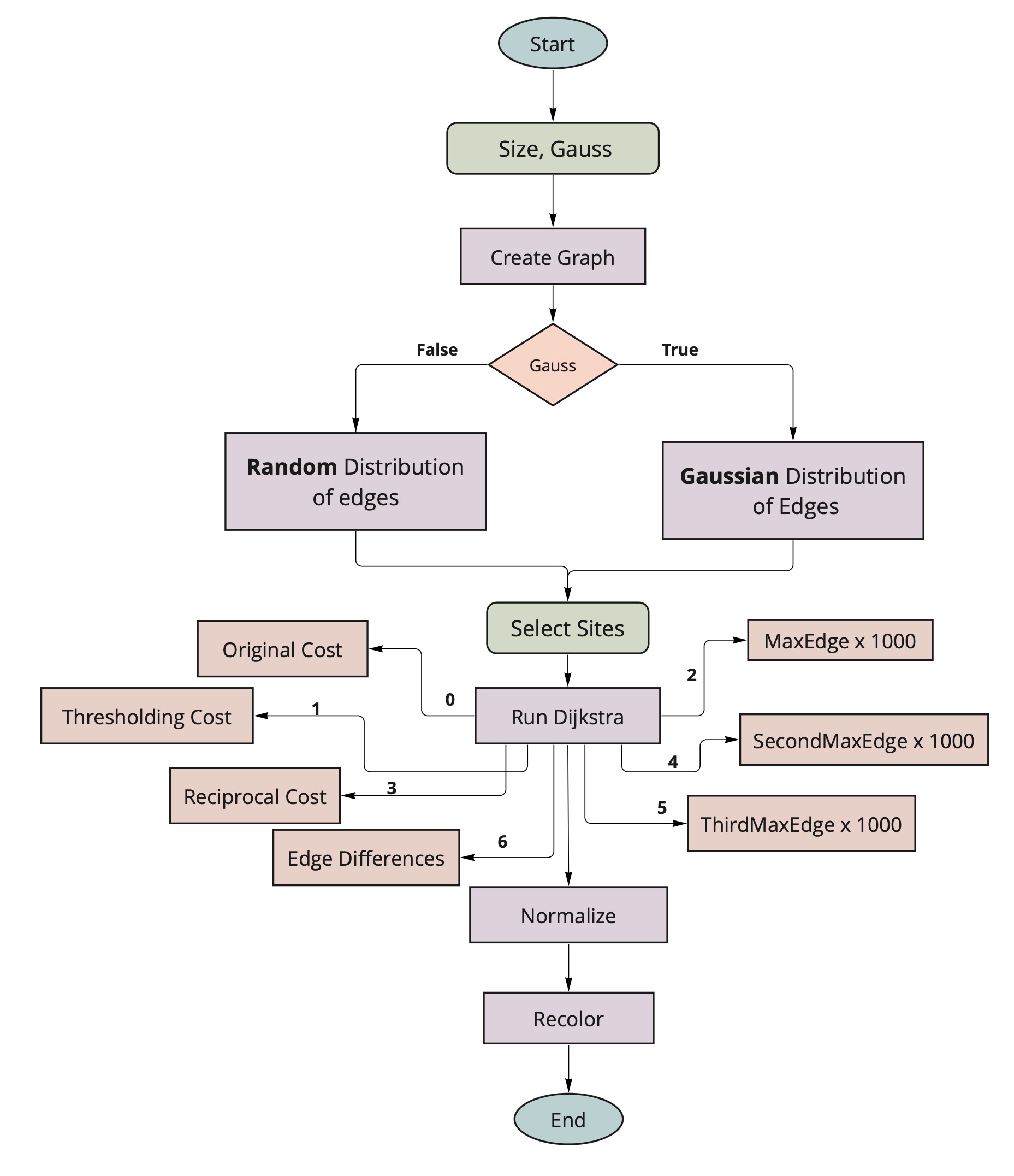
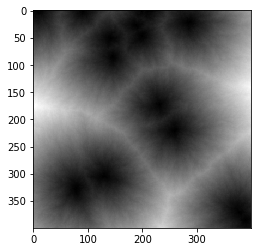
PROJECT 3: Artistic Images with Dijsktra's Algorithm
Inspired by the various elements in rocks and stones, used Dijkstra's algorithm to create artistic images
from a graph structure.
Taking each pixel as a node and connecting it 4-ways with its neighbors, intiated the cost to infinite at the beginning
Used 2 distributions to distribute the edge weights : Guassian and Random
Based on the distributions, selected sites as user inputs from where dispersion will occur.
Run Dijsktra's algorithm from all the sites/source points.
Used various types of costs for experimentations : Usual cost, thresholding cost, using a reciprocal of the costs, edge differences,
putting extra weight of maximum edges,etc.
Normalized and recolored the resulting images
What I've Learned from DeepLearning.ai Specialization (2019)
Emotion Detection Model
A model built with CNN that detects if a person is happy based on their smiles using Keras in Python. The train accuracy is 99% while test accuracy is 97%.
Training set = 600 pictures of size (600,64,64,3) and
Test-set = 150 pictures of size (10,64,64,3)
Face Recognition Model
What's the difference between face verification and recognition?
Face verification is a simpler task that involves matching the input image with the claimed person's image. It is a 1:1 matching problem!
However, face recognition is a bit more complex. It is matching a given input image across a database of images to find who the particular individual
is. It is a 1:K matching problem!
Both face recognition and verification are applied here with triplet loss function and a pre-trained model to map face images into 128-dimensional
encodings. Numpy,Keras, Tensorflow, pandas, cv2 are used to build this model.
Neural Style Transfer
I absolutely LOVE this project as it generates ART with neural networks.
Neural Style Transfer algorithm is used to merge an image's content with another image's style to output unique styled art. A pre-trained model is used to do this task
Content cost function is used using tensorflow. Style cost is computed using Style Matrix( Gram Matrix) and Style Weights. Total cost is the addition of these costs with added weights and Adam optimizer is used.
Libraries used are matplotlib, numpy, pprint, scipy,tensorflow, PIL, etc.
Autonomous Driving using YOLO algorithm
Here, we are mainly creating object detection on a car detection dataset and dealing with bounding boxes
Libraries used : keras,numpy,scipy,matplotlib, tensorflow, pandas,PIL
"You Only Look Once" (YOLO) performs object detection, and then can be applied it to car detection. As YOLO model is very computationally expensive to train, we have loaded pre-trained weights. It is a popular algorithm because it achieves high accuracy while also being able to run in real-time. This algorithm "only looks once" at the image in the sense that it requires only one forward propagation pass through the network to make predictions. After non-max suppression, it then outputs recognized objects together with the bounding boxes.
The YOLO architecture is: IMAGE (m, 608, 608, 3) -> DEEP CNN -> ENCODING (m, 19, 19, 5, 85).
The input is a batch of images, and each image has the shape (m, 608, 608, 3)
The output is a list of bounding boxes along with the recognized classes.
Anchor boxes are chosen by exploring the training data to choose reasonable height/width ratios that represent the different classes.